
<p align="center">
🤗 <a href="https://huggingface.co/datasets/THUDM/LongBench" target="_blank">HF Repo</a> • 📃 Paper coming soon!
</p>
Read this in [English](README.md).
# LongBench: 多任务中英双语长文本理解评测基准
**LongBench**是第一个多任务、中英双语、针对大语言模型**长文本理解能力**的评测基准。在目前大模型多语言能力引起广泛关注的背景下,LongBench涵盖了不同的语言(中文和英文),以此来对大模型在长文本下的多语言能力进行更全面的评估。同时,LongBench由六大类、二十个不同的任务组成,覆盖了单文档QA、多文档QA、摘要、Few-shot学习、代码补全和合成任务等关键的长文本应用场景。
我们深知模型评测过程中可能产生的高昂成本,尤其是长文本场景下(如人工标注成本或API调用成本)。因此,我们采用了一种全自动的评测方式,旨在以最低的成本,最有效地衡量和评估模型的长文本理解能力。
LongBench包含13个英文任务、5个中文任务和2个代码任务,多数任务的平均长度在5k-15k之间,共包含约4500条测试数据。关于LongBench数据集的具体统计及任务构造方式请参考[这里](task_zh.md)。
| 任务类型 | 英文任务数 | 中文任务数 | 代码任务数 |
| :----------: | :--------: | :--------: | :--------: |
| 单文档QA | 3 | 1 | - |
| 多文档QA | 3 | 1 | - |
| 摘要 | 2 | 1 | - |
| Few-shot学习 | 3 | 1 | - |
| 合成任务 | 2 | 1 | - |
| 代码补全 | - | - | 2 |
## 目录
- [排行榜](#排行榜)
- [如何在LongBench上评测模型](#如何在LongBench上评测模型)
- [详细评测结果](#详细评测结果)
- [致谢](#致谢)
- [引用](#引用)
## 排行榜
我们在这里展示了所有模型在Zero-shot场景下,在中文和英文各大类任务上得分的平均值(%),各任务评估所用指标请参考[这里](task_zh.md)。
> 注:对于超出模型处理长度能力的文本,参考[Lost in the Middle](https://arxiv.org/abs/2307.03172)的观察,我们从文本中间进行截断,保持前后部分的信息。实验表明,这种截断方式对模型性能影响最小。
#### 英文榜单
| | Avg | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 | 合成任务 |
| --- | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
| GPT-3.5-Turbo-16k | 45.5 | 39.8 | 38.7 | 26.5 | 76.0 | 54.5 | 37.8 |
| Llama2-7B-chat-4k | 29.0 | 24.8 | 21.4 | 23.9 | 50.5 | 47.3 | 5.9 |
| LongChat-7B-16k | 33.7 | 29.3 | 16.1 | 25.8 | 59.9 | 57.0 | 14.2 |
| XGen-7B-8k | 28.7 | 24.5 | 20.4 | 24.8 | 58.7 | 38.0 | 5.6 |
| InternLM-7B-8k | 24.7 | 17.1 | 20.8 | 13.3 | 52.7 | 39.7 | 4.7 |
| ChatGLM2-6B | 26.0 | 23.1 | 15.0 | 22.9 | 46.1 | 46.1 | 2.7 |
| ChatGLM2-6B-32k | 42.7 | 32.8 | 34.0 | 28.6 | 68.1 | 52.7 | 39.8 |
#### 中文榜单
| | Avg | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 | 合成任务 |
|-------|:---:|:-------------:|:------------:|:-------------:|:-----------------:|:---------------:|:----------------:|
| GPT-3.5-Turbo-16k | 44.5 | 61.2 | 28.7 | 16.0 | 29.2 | 54.5 | 77.5 |
| Llama2-7B-chat-4k | 13.5 | 11.6 | 1.9 | 0.2 | 19.8 | 47.3 | 0.5 |
| LongChat-7B-16k | 23.7 | 26.6 | 19.1 | 14.0 | 20.8 | 57.0 | 4.8 |
| XGen-7B-8k | 14.5 | 14.2 | 9.1 | 1.5 | 20.0 | 38.0 | 4.2 |
| InternLM-7B-8k | 18.6 | 33.3 | 8.9 | 13.0 | 15.5 | 39.7 | 0.9 |
| ChatGLM2-6B | 22.5 | 33.0 | 15.2 | 14.6 | 20.5 | 46.1 | 5.5 |
| ChatGLM2-6B-32k | 41.3 | 52.0 | 34.3 | 16.3 | 29.9 | 52.7 | 62.5 |
#### 长文本任务能力雷达图

#### 不同长度文本下的能力变化
为了更有针对性地分析模型在不同文本长度下的相对表现,下图展示了模型在不同文本长度区间上,所有任务上的平均相对分数。
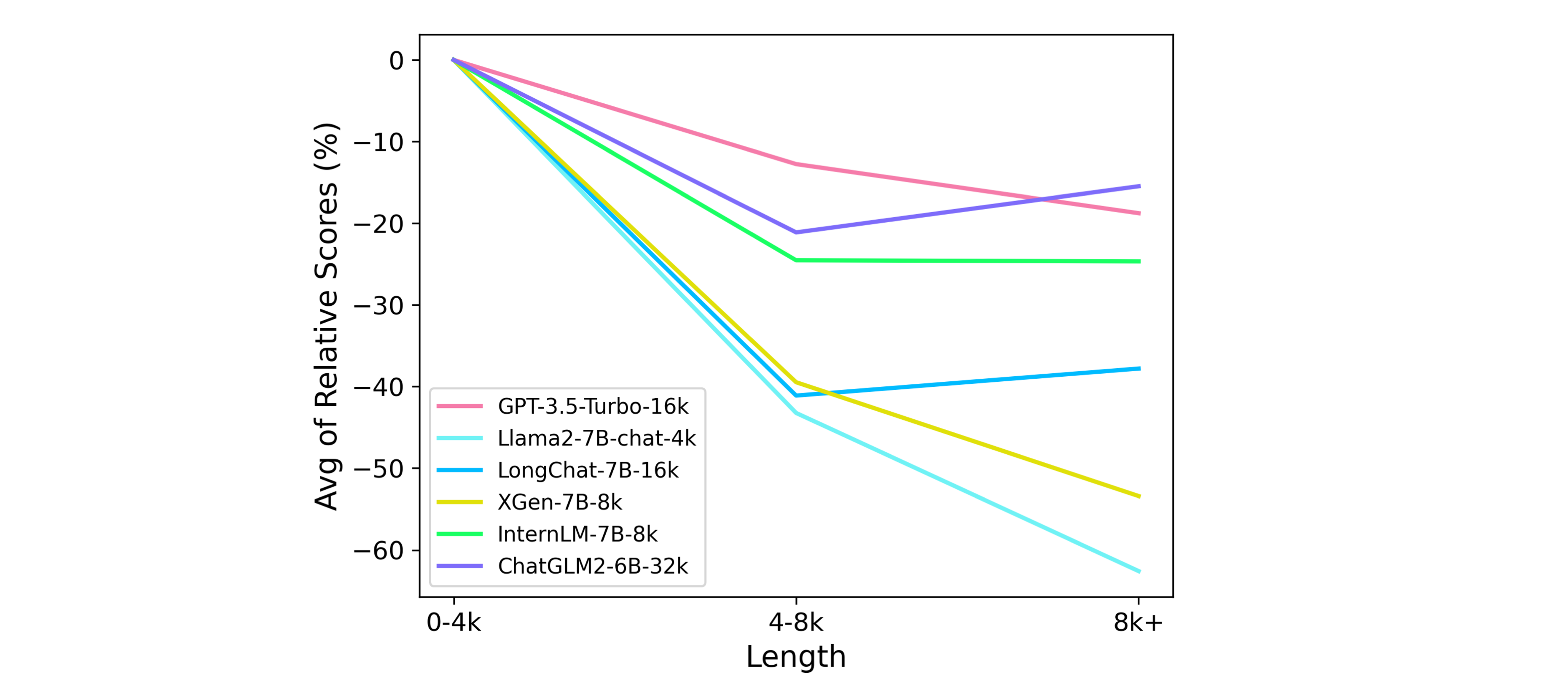
> 注:假设模型在某个任务的特定长度范围内数据上得分为x,在该任务所有数据上得分为y,则模型在该长度范围的**相对分数**为(x/y-1)。为了更好比较不同模型的变化趋势,我们在0-4k将所有折线平移至0。
## 如何在LongBench上评测模型
#### 载入数据
你可以通过Hugging Face datasets来下载并载入**LongBench**的数据([🤗 HF Repo](https://huggingface.co/datasets/THUDM/LongBench)):
```python
from datasets import load_dataset
datasets = ["hotpotqa", "2wikimqa", "musique", "dureader", "narrativeqa", "qasper", "multifieldqa_en", \
"multifieldqa_zh", "gov_report", "qmsum", "vcsum", "trec", "nq", "triviaqa", "lsht", "passage_count", \
"passage_retrieval_en", "passage_retrieval_zh", "lcc", "repobench-p"]
for dataset in datasets:
data = load_dataset('THUDM/LongBench', dataset, split='test')
```
同样地,你也可以直接用这个[链接](https://huggingface.co/datasets/THUDM/LongBench/resolve/main/data.zip)下载所有的评测数据。
#### 数据格式
**LongBench**中所有数据都统一为以下格式:
```json
{
"input": "任务的输入/指令,通常较短,比如QA中的问题、Few-shot任务中的提问等",
"context": "任务所需的长语境文本,比如文档、跨文件代码、Few-shot任务中的few-shot样本",
"answers": "由所有标准答案组成的列表",
"length": "前三项文本的总长度(中、英文分别用字、词数统计)",
"dataset": "本条数据所属数据集名称",
"language": "本条数据的语言",
"all_classes": "分类任务中的所有类别,非分类任务则为null",
"_id": "每条数据的随机id"
}
```
#### 评测
通过pip安装依赖:`pip install -r requirements.txt`。我们以ChatGLM2-6B为例提供了一份评测代码。首先,运行仓库下的[pred.py](pred.py)
```bash
CUDA_VISIBLE_DEVICES=0 python pred.py
```
可以在`pred/`文件夹下得到模型在所有数据集下的输出,此后运行[eval.py](eval.py)的评测代码:
```bash
python eval.py
```
可以在`result.json`中得到在各数据集上的评测结果。请注意,我们在`config/`下提供了我们总结出来的在各数据集上适合的输入格式和最大输出长度限制,在评测的时候可以进行修改以更好地适用你要评测的模型,修改后在[pred.py](pred.py)评测时会自动按照新的格式去整理数据并得到对应的模型输出。
## 详细评测结果
下面的几张表格展示了模型在所有子任务数据集上的Zero-shot评测结果(%),其中的中文数据集以“zh”标示(各任务评估所用指标请参考[这里](task_zh.md))。
#### 单文档QA
| | NarrativeQA | Qasper | MultiFieldQA-en | MultiFieldQA-zh |
|-------------------|:-----------:|:------:|:---------------:|:---------------:|
| GPT-3.5-Turbo-16k | 23.6 | 43.3 | 52.3 | 61.2 |
| Llama2-7B-chat-4k | 19.1 | 19.6 | 35.8 | 11.6 |
| LongChat-7B-16k | 21.6 | 21.6 | 44.6 | 26.6 |
| XGen-7B-8k | 17.9 | 18.3 | 37.2 | 14.2 |
| InternLM-7B-8k | 12.4 | 16.8 | 22.3 | 33.3 |
| ChatGLM2-6B | 11.2 | 23.7 | 34.2 | 33.0 |
| ChatGLM2-6B-32k | 20.4 | 32.2 | 45.7 | 52.0 |
#### 多文档QA
| | HotpotQA | 2WikiMQA | Musique | DuReader (zh) |
|----------------------|:--------:|:--------:|:-------:|:--------:|
| GPT-3.5-Turbo-16k | 51.6 | 37.7 | 26.9 | 28.7 |
| Llama2-7B-chat-4k | 24.3 | 31.4 | 8.6 | 1.9 |
| LongChat-7B-16k | 22.4 | 16.8 | 9.1 | 19.1 |
| XGen-7B-8k | 28.3 | 21.5 | 11.5 | 9.1 |
| InternLM-7B-8k | 27.9 | 24.0 | 10.3 | 8.9 |
| ChatGLM2-6B | 20.2 | 19.6 | 5.3 | 15.2 |
| ChatGLM2-6B-32k | 44.9 | 34.9 | 22.2 | 34.3 |
#### 摘要
| | GovReport | QMSum | VCSUM (zh) |
|:-----------|:---------:|:-----:|:-----:|
| GPT-3.5-Turbo-16k | 29.5 | 23.4 | 16.0 |
| Llama2-7B-chat-4k | 27.3 | 20.6 | 0.2 |
| LongChat-7B-16k | 28.4 | 23.2 | 14.0 |
| XGen-7B-8k | 27.8 | 21.7 | 1.5 |
| InternLM-7B-8k | 9.8 | 16.8 | 13.0 |
| ChatGLM2-6B | 23.7 | 22.2 | 14.6 |
| ChatGLM2-6B-32k | 33.3 | 23.9 | 16.3 |
#### Few-shot学习
| | TREC | NQ | TriviaQA | LSHT (zh) |
| --- | :-: | :-: | :-: | :-: |
| GPT-3.5-Turbo-16k | 68.0 | 73.0 | 87.1 | 29.2 |
| Llama2-7B-chat-4k | 60.5 | 31.4 | 59.7 | 19.8 |
| LongChat-7B-16k | 61.5 | 44.8 | 73.5 | 20.8 |
| XGen-7B-8k | 66.0 | 43.2 | 67.0 | 20.0 |
| InternLM-7B-8k | 49.0 | 47.6 | 61.6 | 15.5 |
| ChatGLM2-6B | 44.0 | 34.5 | 59.8 | 20.5 |
| ChatGLM2-6B-32k | 62.0 | 64.9 | 77.6 | 29.9 |
#### 代码补全
| | LCC | RepoBench-P |
| --- | :-: | :-: |
| GPT-3.5-Turbo-16k | 54.7 | 54.3 |
| Llama2-7B-chat-4k | 52.3 | 42.4 |
| LongChat-7B-16k | 59.2 | 54.7 |
| XGen-7B-8k | 38.8 | 37.3 |
| InternLM-7B-8k | 45.5 | 34.0 |
| ChatGLM2-6B | 48.4 | 43.7 |
| ChatGLM2-6B-32k | 55.4 | 50.0 |
#### 合成任务
| | PassageRetrieval-en | Passage Count | PassageRetrieval-zh |
| --- | :-: | :-: | :-: |
| GPT-3.5-Turbo-16k | 71.0 | 4.5 | 77.5 |
| Llama2-7B-chat-4k | 9.2 | 2.5 | 0.5 |
| LongChat-7B-16k | 24.0 | 4.5 | 4.8 |
| XGen-7B-8k | 9.0 | 2.2 | 4.2 |
| InternLM-7B-8k | 6.5 | 2.9 | 0.9 |
| ChatGLM2-6B | 3.2 | 2.1 | 5.5 |
| ChatGLM2-6B-32k | 77.5 | 2.0 | 62.5 |
## 致谢
- **LongBench**的部分任务基于之前的研究者提出的数据集构建,包括[HotpotQA](https://hotpotqa.github.io/),[2WikiMultihopQA](https://aclanthology.org/2020.coling-main.580/),[Musique](https://arxiv.org/abs/2108.00573),[DuReader](https://github.com/baidu/DuReader),[NarrativeQA](https://arxiv.org/pdf/1712.07040.pdf),[Qasper](https://arxiv.org/pdf/2105.03011.pdf),[GovReport](https://arxiv.org/pdf/2104.02112.pdf),[QMSum](https://arxiv.org/pdf/2104.05938.pdf),[VCSUM](https://arxiv.org/abs/2305.05280),[TriviaQA](https://nlp.cs.washington.edu/triviaqa/),[NQ](https://ai.google.com/research/NaturalQuestions/),[TREC](https://aclanthology.org/C02-1150.pdf),[LSHT](http://tcci.ccf.org.cn/conference/2014/dldoc/evatask6.pdf),[LCC](https://arxiv.org/abs/2306.14893)和[RepoBench-P](https://arxiv.org/abs/2306.03091)。
## 引用
本工作由**THU-KEG**和**Zhipu AI**共同完成,相关论文正在撰写中,届时将更新引用信息,敬请关注~
如果您使用Longbench,请一并引用LongBench所基于的数据集对应的论文,相关引用信息在[这里](refs/ref.bib)。